Lazy Programming Series – Function Caching, Handling Exception, Coroutines & OS Module in Python

Function Caching in Python:
In Python, you can implement function caching using various techniques. Caching helps to store the results of expensive function calls and retrieve them when the same inputs occur again, thereby saving computation time. Here are a few common ways to implement function caching in Python:
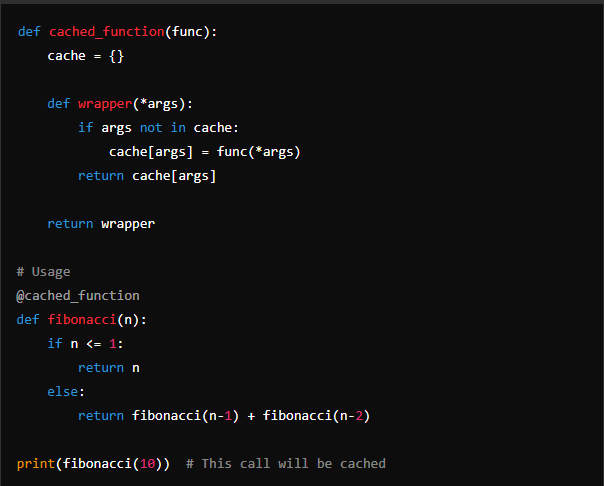
- Using a Dictionary: You can use a dictionary to store the results of function calls with their respective arguments as keys.
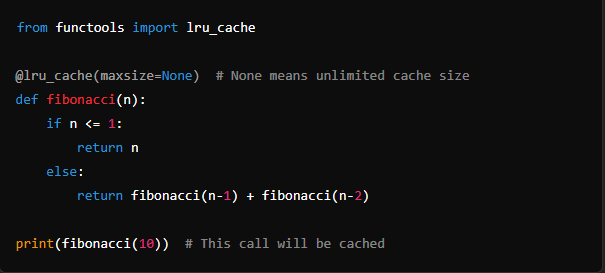
Using functools.lru_cache: Python’s standard library provides the functools.lru_cache decorator, which implements a least-recently-used caching mechanism.
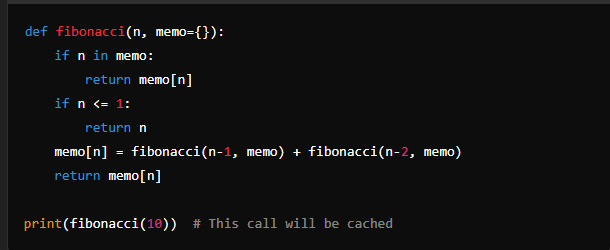
Using Memoization: This is a technique where you explicitly store computed results in a function’s closure.
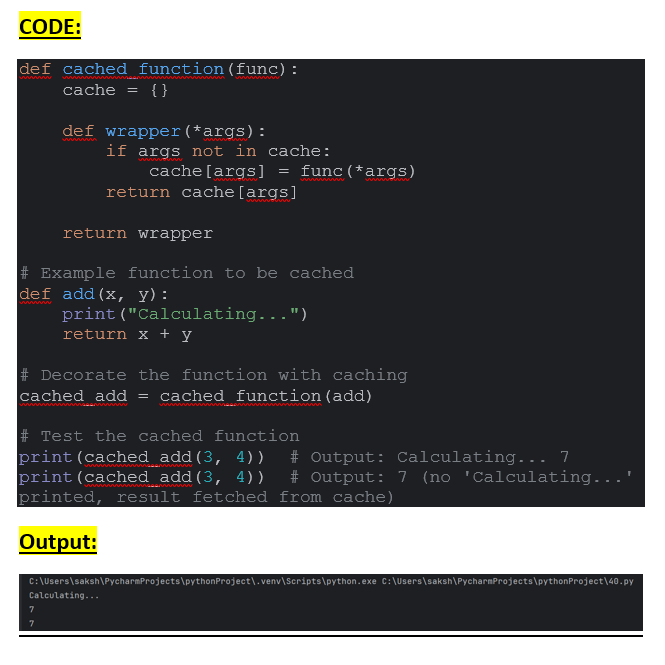
Each of these methods has its own advantages and use cases. Choose the one that best fits your requirements.
Handling Exceptions with try, except, else, and finally in Python
In Python, the try, except, else, and finally blocks provide a powerful mechanism for handling exceptions and executing cleanup code. Let’s explore each of these blocks and their roles within exception handling.
1. try Block:
The try block is used to wrap the code that might raise an exception. Any code within this block that raises an exception will be caught by the subsequent except block(s).
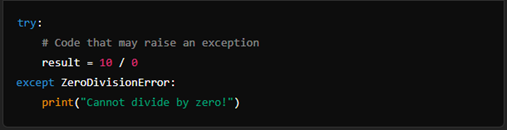
2. except Block:
The except block catches exceptions raised in the corresponding try block. You can specify the type of exception you want to catch, or catch all exceptions using a generic except block.
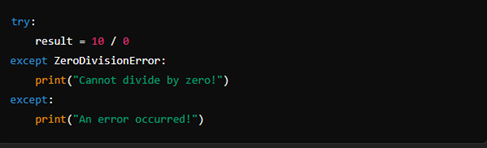
3. else Block:
The else block is executed if no exceptions are raised in the try block. It is often used to place code that should run only if the try block executes successfully.
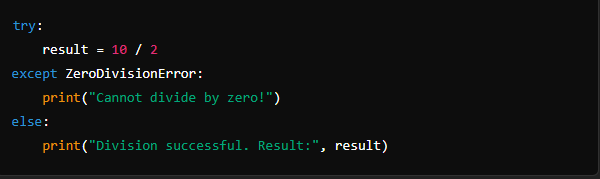
4. finally Block:
The finally block is always executed, regardless of whether an exception occurred or not. It is typically used for cleanup actions, such as closing files or releasing resources.
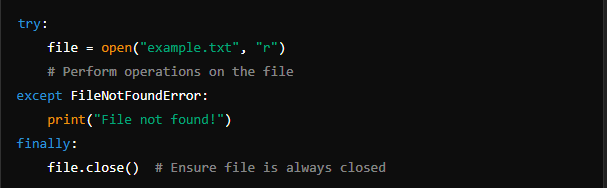
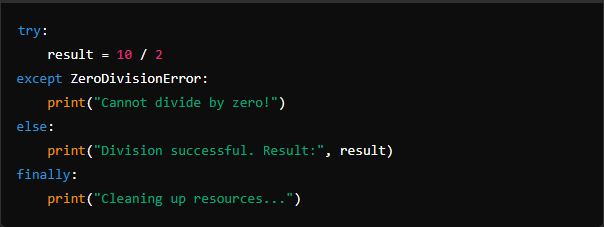
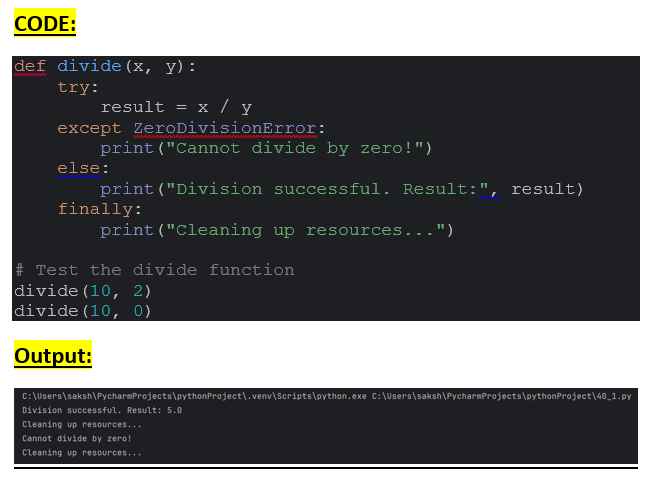
Using else and finally Together:
You can combine else and finally blocks to execute cleanup code after successful execution of the try block.
Coroutines In Python:
Coroutines are a powerful feature in Python that allow for cooperative multitasking, enabling functions to pause execution while retaining their state and later resume from where they left off. Introduced in Python 3.5, coroutines are implemented using the async and await keywords, and they form the basis of asynchronous programming in Python.
Understanding Coroutines
At their core, coroutines are functions that can pause execution at specific points using the await keyword and can be resumed later. Unlike traditional functions, coroutines are not executed all at once; instead, they can yield control back to the event loop, allowing other coroutines to run in the meantime.
Syntax of Coroutines
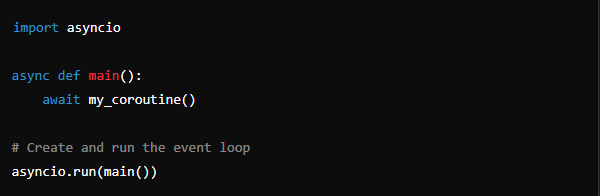
To define a coroutine, you use the async def syntax:

Here, async def declares my_coroutine() as a coroutine function. Within the function body, you can use the await keyword to pause execution until an asynchronous operation, such as an I/O operation or another coroutine, completes.
Executing Coroutines
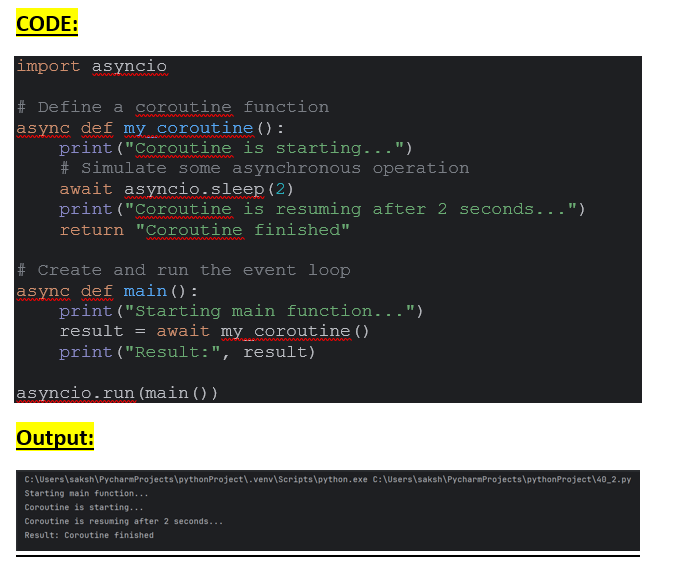
Coroutines are typically executed within an event loop, which schedules and manages their execution. The asyncio module in Python provides an event loop implementation for asynchronous programming. Here’s how you can execute a coroutine within an event loop:
In this example, main() is a coroutine function that calls my_coroutine() using await. The asyncio.run() function is then used to run the event loop and execute the coroutine.
Benefits of Coroutines
- Concurrency: Coroutines enable concurrent execution of multiple tasks within a single thread, making efficient use of system resources.
- Asynchronous I/O: Coroutines are well-suited for asynchronous I/O operations, such as reading from files, making network requests, or interacting with databases, without blocking the main thread.
- Stateful Execution: Coroutines can retain their state between successive invocations, allowing for more complex and flexible control flow compared to regular functions.
OS Module:
The os module in Python provides a platform-independent way of interacting with the operating system. It allows you to perform various operating system-related tasks, such as navigating the file system, manipulating environment variables, and executing system commands.
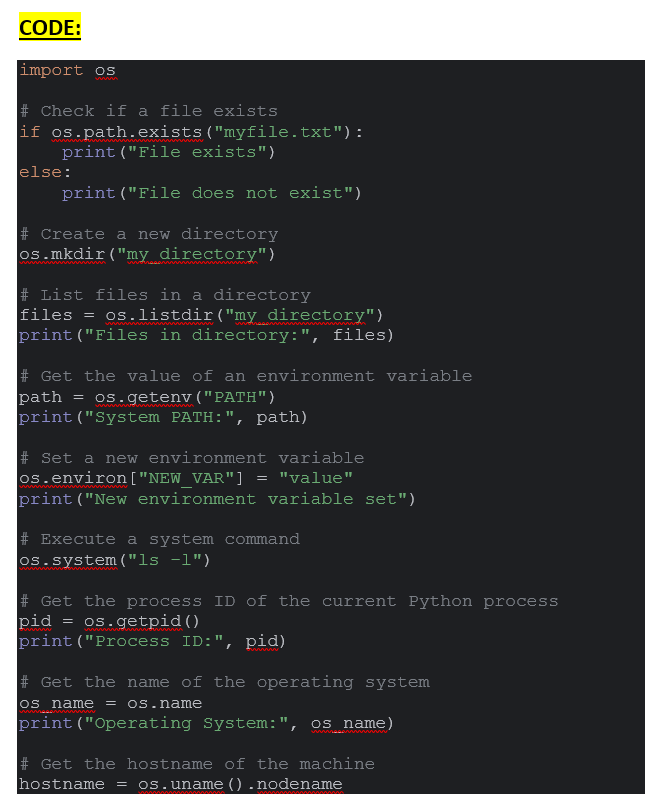
1. File and Directory Operations
The os module enables you to work with files and directories on the file system. You can create, delete, rename, and traverse directories, as well as check file properties such as existence, size, and permissions.
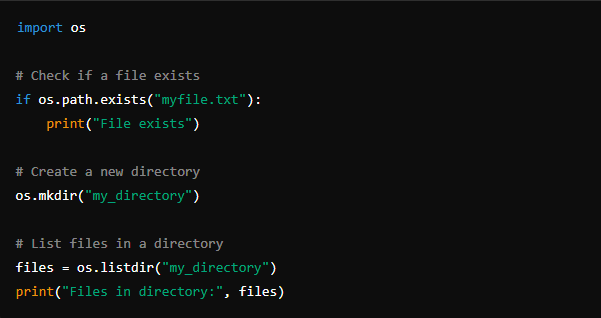
2. Environment Variables
You can access and modify environment variables using the os module. This allows you to interact with the environment in which your Python script is running, accessing information such as system paths, user settings, and configuration variables.
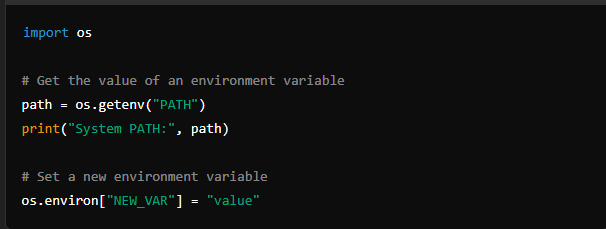
3. Process Management
The os module provides functions for interacting with processes, such as spawning new processes, retrieving process IDs, and terminating processes.
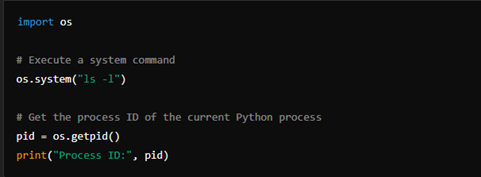
4. Platform Information
You can retrieve information about the underlying operating system using the os module. This includes details such as the name of the operating system, the machine’s hostname, and system-specific constants.
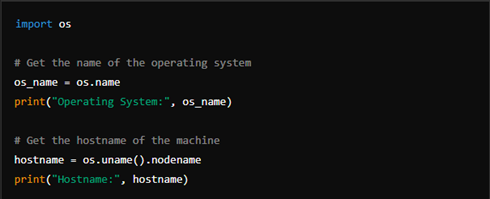
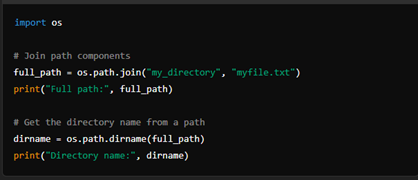
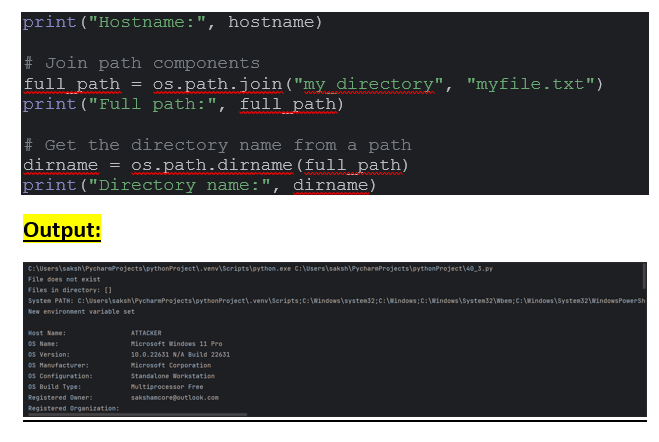
5. File Path Manipulation
The os.path submodule provides functions for manipulating file paths in a platform-independent manner. This includes joining and splitting path components, checking file extensions, and retrieving directory names
@SAKSHAM DIXIT
Related Posts

Lazy Programming Series – Advanced List Slicing, Bisect Module, Format & Join Function, Is vs == in Python
Lazy Programming Series – Challenge – 8